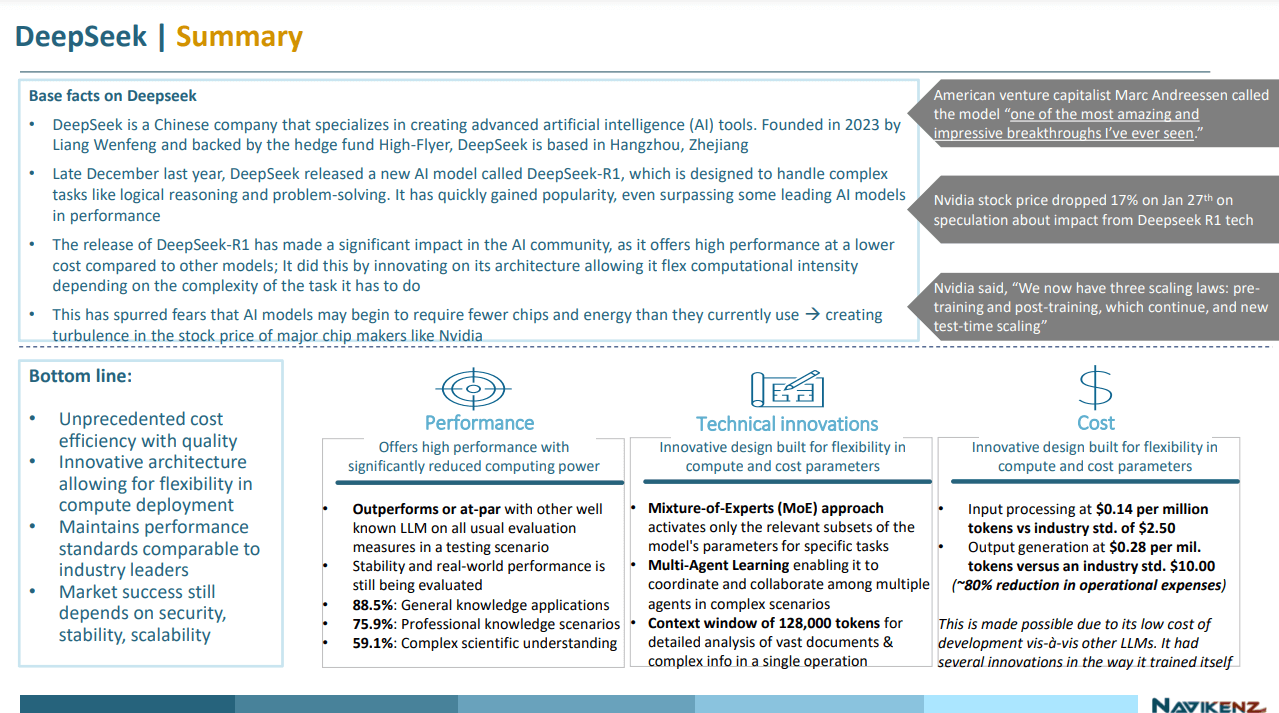
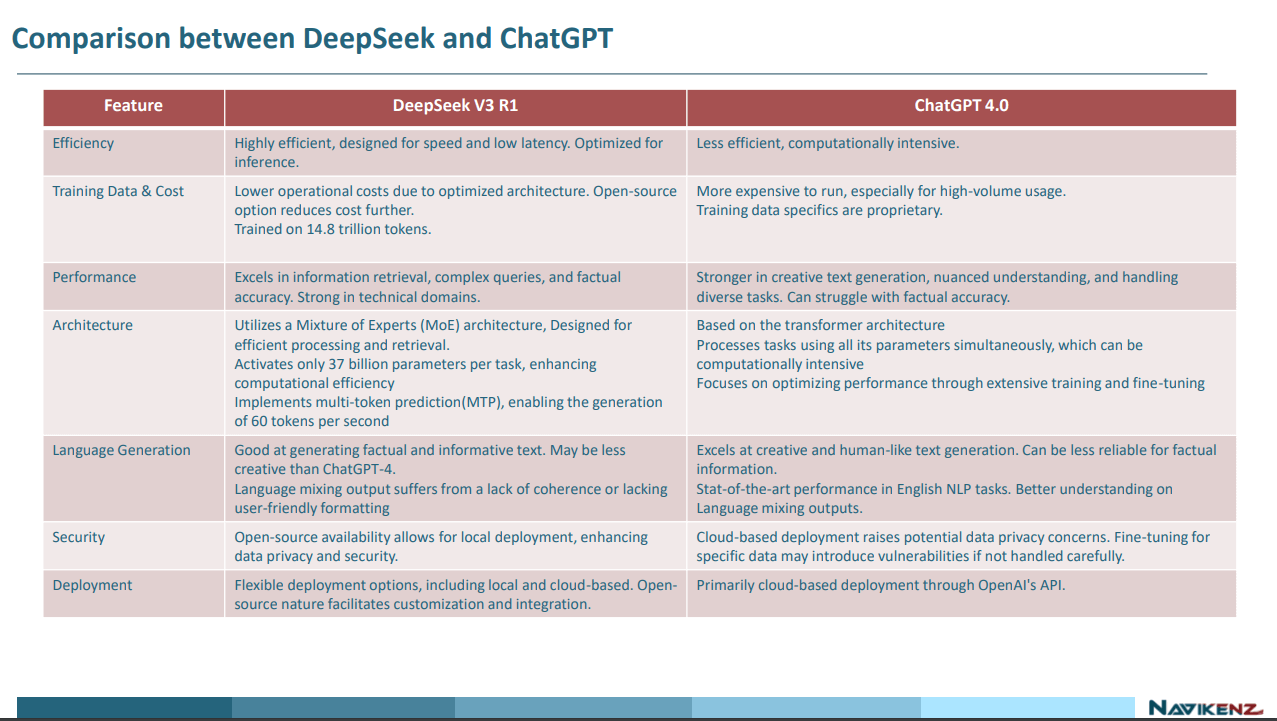
Deepseek’s innovations will lower entry barriers and accelerate the pace of AI-driven advancements.
Industry leaders will step up to the challenge, driving improved market economics.
As LLMs become more commoditized, true differentiation will come from solution developers creating unique, value-driven applications.
At Navikenz, our mission is to empower human enterprise with AI to shape a new digital future. With our LLM-based frameworks and solutions, we anticipate even greater economic returns as computing costs continue to decline.
The healthcare sector in India is evolving significantly, driven by Artificial Intelligence (AI) and advanced analytics. As the nation’s population grows and patient needs become more complex, healthcare providers face increasing demands to streamline operations, deliver personalized care, and improve clinical outcomes. Like a compass guiding through complex terrain, AI is becoming an essential tool for addressing these challenges by automating routine processes, enhancing patient care, and broadening access to vital health services. This article explores AI’s role in healthcare operations and highlights Navikenz’s contributions to advancing Indian healthcare through its AI-driven solutions.
Healthcare facilities across India handle extensive administrative processes—patient registration, billing, insurance claims—that often consume significant time and resources. Such tasks can create bottlenecks, slowing down patient care. AI-driven automation functions as an “invisible workforce,” efficiently performing these repetitive tasks, allowing healthcare staff to focus more on patient-centered activities.
Consider Fortis Hospital, where AI-powered automation of insurance claims has noticeably accelerated processing times. This automation extracts, validates, and submits claims data, reducing errors and speeding up reimbursements. Similarly, AI solutions in hospitals optimize workflows, automate scheduling, and streamline patient record management. This enables medical staff to dedicate more time to patients, underscoring how AI’s “digital concierge” role eases operational barriers and refocuses energy on care.
Personalized Patient Care: From Assembly Line to Custom Craftsmanship
In the past, healthcare often resembled an assembly line, with patients moved between departments and one-size-fits-all treatments. AI is shifting this dynamic by enabling personalized care—a transition similar to moving from mass production to bespoke craftsmanship.
Apollo Hospitals’ use of conversational AI illustrates this shift, providing patients with immediate, 24/7 assistance. AI-powered chatbots answer patient inquiries, schedule appointments, and manage follow-ups, reducing wait times and ensuring accessible care. Additionally, through AI-based training programs, hospitals can assess healthcare staff’s needs and deliver targeted learning experiences, leading to higher service quality and improved patient outcomes.
Data-Driven Insights: The Crystal Ball of Healthcare
AI-powered analytics provide healthcare providers with a “crystal ball,” allowing them foresight into patient trends and resource needs. Through data-driven insights, healthcare organizations can make informed decisions, optimizing operations and planning resources effectively.
For instance, AI’s predictive analytics capabilities forecast patient admissions at Mt. Sinai Hospital, enabling efficient allocation of beds, staff, and supplies. This capability is especially crucial in managing outpatient departments, where overcrowding can impact care quality. Real-time dashboards further assist healthcare leaders by presenting comprehensive insights, allowing for quick adjustments to meet patient needs. AI’s predictive power shifts decision-making from reactive to proactive, enhancing operational efficiency.
Regulatory Compliance: A Reliable Sentinel
Navigating healthcare’s regulatory environment is challenging, with stringent requirements like those from CDSCO and NABH. AI acts as a “reliable sentinel,” ensuring healthcare providers stay compliant with evolving standards, avoiding penalties, and safeguarding patient trust.
NaviScript.AI from Navikenz simplifies this by automating compliance reporting, reducing manual workloads, and ensuring timely submissions. AI also proactively identifies regulatory risks, allowing healthcare providers to implement preventive measures. By integrating AI, compliance management becomes less burdensome, supporting quality and ethical healthcare practices.
Accelerating Drug Discovery and Clinical Trials: Fast-Tracking Innovation
In India’s expanding pharmaceutical landscape, drug discovery and clinical trials are critical but often costly and time-consuming. AI serves as a “digital research assistant,” expediting these processes while maintaining accuracy and reducing costs.
At Dr. Reddy’s Laboratories, AI aids in drug discovery by analyzing molecular interactions to identify promising drug candidates faster than traditional methods. AI also optimizes clinical trials by predicting participant behavior and streamlining enrollment, reducing trial costs while enhancing accuracy. In a field where “time equals lives,” AI’s impact on accelerating these processes is invaluable.
Telemedicine: Bridging the Urban-Rural Healthcare Divide
In India, where access to healthcare services remains a challenge for rural communities, AI-powered telemedicine solutions act as a “virtual bridge,” extending essential services across geographical barriers.
AI-enabled wearables, for instance, allow doctors to remotely monitor patient vitals, identifying health anomalies in real-time. Such devices benefit chronic disease management, reducing hospital visits and enabling timely interventions. Telehealth platforms used by AIIMS Delhi further connect patients in remote areas with specialists, effectively broadening healthcare access. AI-powered telemedicine isn’t just a solution—it’s a crucial lifeline for communities in need.
Navikenz: A Partner in India’s Healthcare Transformation
Navikenz specializes in AI-driven solutions that address the needs of healthcare providers in India. With extensive expertise in Generative AI, advanced analytics, and data engineering, Navikenz enables organizations to optimize operations, enhance patient care, and ensure regulatory compliance.
Why Navikenz is the Right Partner for Indian Healthcare Providers
Industry Expertise: With over 250 years of combined experience in IT services & Digital Transformation, Navikenz offers solutions designed to meet operational and clinical challenges.
Comprehensive AI Solutions: Navikenz provides end-to-end services, from workflow automation and predictive analytics to compliance management, driving efficiency and patient satisfaction.
Proven Track Record: Innovative platforms like NaviGen and NaviScript.ai ensure compliance with both Indian and global healthcare standards, solidifying Navikenz as a trusted industry leader.
The Future of AI in Indian Healthcare: Paving the Road Ahead
As India moves forward in digital transformation, AI will play an increasingly central role in addressing operational efficiency, compliance, and personalized care. With greater investments in AI-powered healthcare technologies, such as telemedicine and remote monitoring, access to quality care will continue to expand across both urban and rural areas.
With Navikenz as a strategic partner, healthcare providers gain specialized expertise, innovative AI solutions, and a commitment to measurable results
Conclusion
AI is reshaping healthcare in India by automating workflows, personalizing patient care, and providing insights that drive strategic decision-making. Healthcare providers embracing AI will be better prepared to meet India’s healthcare demands, ultimately enhancing patient outcomes and operational performance.
With Navikenz’s AI solutions, organizations can unlock new efficiencies, streamline operations, and elevate patient care. Let Navikenz be your guide in this journey toward an AI-enabled future tailored to India’s unique needs.
The urgent care industry in the United States has experienced remarkable growth over the past decade, nearly doubling from 7,220 centers in 2014 to 15,032 as of January 2025.[1] This rapid expansion underscores the highly competitive and elastic nature of the market, where patient choices are abundant, and switching costs are minimal. In such a dynamic environment, understanding and enhancing patient satisfaction and loyalty are paramount for urgent care centers aiming to differentiate themselves and retain their patient base.
Net Promoter Score (NPS), in particular, is a key metric for urgent care centers (UCCs), providing valuable insights into patient experiences and overall satisfaction. A high NPS indicates positive patient experiences, leading to better retention and strong word-of-mouth referrals. By benchmarking NPS against industry standards, UCCs can identify areas for improvement, set realistic goals, and enhance service delivery. Focusing on NPS helps drive performance improvements and positions urgent care centers as leaders in patient care.
How is NPS Measured?
NPS measures patient loyalty by assessing the likelihood of patients recommending a service to others. Patients are categorized as Promoters (scores 9-10), Passives (scores 7-8), or Detractors (scores 0-6). The NPS is calculated by subtracting the percentage of Detractors from the percentage of Promoters, yielding a score between -100 and +100.[2]
Industry Benchmarks: Where Do Urgent Care Centers Stand?
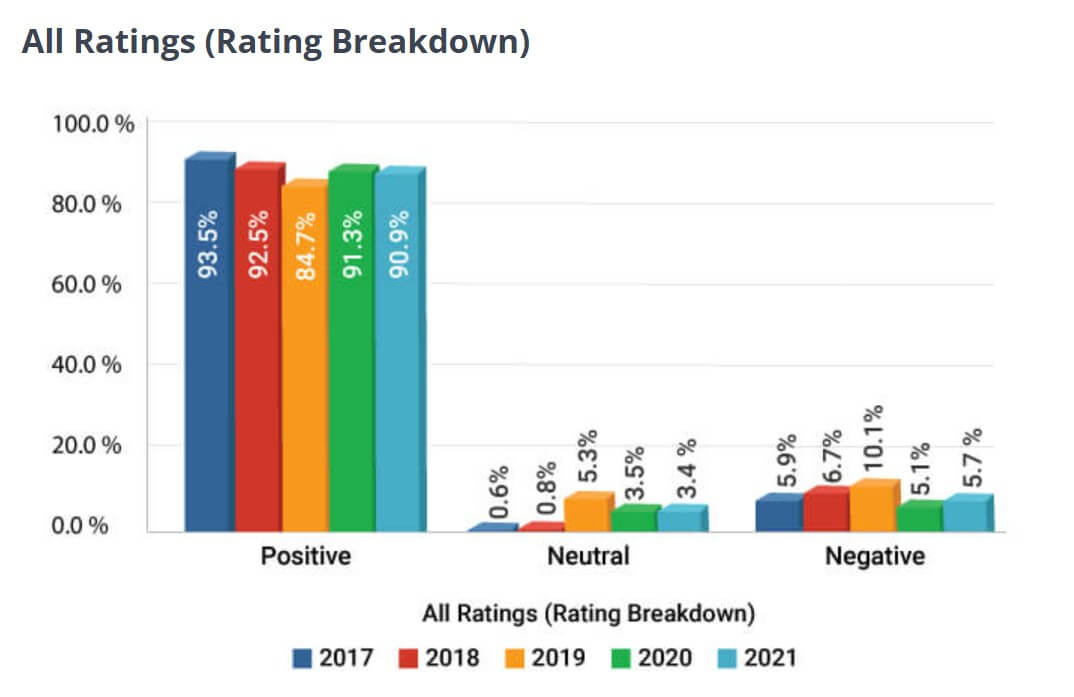
Analyzing industry benchmarks for Net Promoter Scores (NPS) in urgent care centers reveals a consistent trend of high patient satisfaction and loyalty. According to a 2021 survey by GMR Web Team among 17756 patients, the overall NPS for urgent care centers was 76.5 out of 100, indicating a strong likelihood of patients recommending these services.[3]
(Source: GMR Web Team)
Similarly, a review of over 928,000 surveys collected through Experity Patient Engagement reported an average NPS of 86 for urgent care centers, further emphasizing the positive patient experiences in this sector.[4] These figures suggest that urgent care centers generally outperform the broader healthcare industry, which has an average NPS of 58.[5]
Maintaining or exceeding these benchmark scores is crucial for urgent care centers aiming to enhance patient satisfaction and foster loyalty.
Improving Your NPS Scores
Enhancing your Net Promoter Score (NPS) is essential for fostering patient loyalty and improving overall service quality in your urgent care center. Implementing strategies such as streamlining patient flow to reduce wait times and problems of over and understaffing, clearly communicating diagnoses and treatment plans, training staff in active listening and empathy, regularly collecting and responding to patient feedback, following up with dissatisfied patients, maintaining a clean and comfortable environment, investing in staff training on patient-centered care and effective communication, and streamlining administrative processes can significantly improve patient experiences. By focusing on these areas, your urgent care center can enhance patient satisfaction, leading to higher NPS, increased patient loyalty, and a stronger reputation in the healthcare community.
Conclusion
It is time to introspect:
Are you meeting the industry benchmark for NPS Score?
Have you identified areas for improvement based on patient feedback?
Is your center leveraging advanced solutions to enhance patient experience?
By implementing targeted strategies and leveraging advanced solutions, such as those offered by Navikenz, your center can help you solve these problems, improve patient experiences and operational efficiency and achieve higher satisfaction & loyalty scores.
Contact us today to learn how we can help you transform your patient experience and achieve measurable improvements in satisfaction and loyalty at info@navikenz.com.
Imagine stepping into a store where every aisle, every product recommendation feels as if it was curated just for you. This personalized shopping experience isn’t merely a dream but a reality powered by artificial intelligence (AI), which is rapidly transforming the Indian retail landscape. As major players like Amazon India, Flipkart, and Myntra lead this technological renaissance, AI has become the engine driving efficiency, predicting trends, and offering tailored journeys for each consumer in a competitive and evolving marketplace.
How AI is Revolutionizing Retail in India
Personalized Product Recommendations: Your Digital Personal Shopper
Picture an attentive personal shopper who knows your taste, budget, and style, presenting just the right options as you walk through the aisles. AI algorithms analyze patterns from browsing history, purchase records, and even demographics to act as this virtual personal shopper. For example, Flipkart and Amazon India use AI-powered recommendation engines that anticipate consumer preferences, turning casual browsers into loyal buyers. This level of personalization not only satisfies customers but also fuels conversion rates—much like a store attendant who knows exactly what a customer wants before they do.
Visual Search and Augmented Reality (AR): A Virtual Dressing Room
Imagine trying on a dozen pairs of sunglasses without ever setting foot in a store. Retailer Lenskart has introduced AI-powered visual search and AR, allowing customers to virtually “try on” eyewear from home. This tool is like a digital mirror, removing the uncertainty of online shopping and building consumer confidence, much like the experience of trying on items in a fitting room. As a result, customers are more likely to make satisfying purchases, reducing the need for returns and fostering trust in the retailer.
Chatbots and Virtual Assistants: The Customer Service Representative That Never Sleeps
Think of a customer service representative who’s always available, ready to answer questions, recommend products, and resolve issues—all without breaks. Myntra’s AI-powered chatbots serve this role, responding to customer queries in real-time and offering guidance that feels personalized. These bots don’t just reduce costs; they enhance the shopping journey by providing assistance exactly when it’s needed, much like having a helpful assistant by your side during every shopping experience.
Demand Forecasting and Inventory Management: The Fortune Teller for Retailers
Retail success often hinges on having the right product at the right time. AI acts as a modern fortune teller, predicting customer demand with remarkable accuracy. By analyzing historical data, purchasing patterns, and market trends, AI helps retailers like Big Bazaar stock products efficiently, preventing the nightmare of empty shelves and wasteful overstock. With predictive analytics, AI enables retailers to walk the fine line between demand and supply, ensuring that the right products are available just when customers need them.
Dynamic Pricing Strategies: Adapting Like a Market Vendor
In India’s price-sensitive market, imagine a vendor who adapts prices based on the crowd, time of day, and even local competition. AI enables this same flexibility at scale, analyzing competitor prices, demand fluctuations, and consumer behavior in real time to adjust prices dynamically. Just as a skilled market vendor remains competitive without compromising on profit, AI-driven pricing strategies help Indian retailers attract price-sensitive customers while safeguarding margins.
Creating Seamless Omnichannel Retailing in India with AI
Omnichannel retailing is like weaving a seamless tapestry that blends online and in-store experiences. Today’s consumer expects to start their journey on a mobile app, browse products online, and make purchases in-store, all without friction. AI bridges these channels, turning scattered threads into a cohesive story. AI-powered chatbots, for example, enable conversational commerce, creating a smooth user journey across digital and physical platforms. This integration builds brand loyalty, much like a personalized shopping assistant who guides the customer seamlessly across touchpoints, always attentive to their unique needs.
Leveraging Data for Personalization at Scale
Effective personalization is like handcrafting a tailored suit—it requires precise measurements and detailed understanding. In the retail world, this tailoring is powered by rich, high-quality data. AI systems harness demographic and psychographic insights to craft targeted campaigns, helping retailers engage customers on a more intimate level. Reliance Trends exemplifies this by employing AI-driven micro-profiling to offer curated recommendations and exclusive deals. With AI, each customer’s experience is akin to stepping into a store where every product feels like it was selected just for them.
Challenges in Implementing AI in Indian Retail
Algorithm Bias and Fairness: The Unseen Filters
Imagine shopping through tinted glasses that distort colors—this is what biased AI can feel like. If AI models are trained on incomplete data, they risk developing biases that result in unfair recommendations. To prevent this, retailers must treat data as a trusted mirror, conducting regular audits and using diverse datasets to ensure AI reflects an inclusive view of the customer base.
Data Privacy and Security: The Lock and Key of Consumer Trust
In a world where data is like currency, privacy and security are the vault. India’s Digital Personal Data Protection Act serves as the guard, mandating rigorous measures like encryption and anonymization to protect consumer information. For AI-driven retailers, this means securing data with the highest standards and being transparent about its usage, ensuring consumer trust remains unbroken.
Balancing Personalization with Privacy: Walking a Fine Line
Personalization is powerful, but only when balanced with privacy. As Indian consumers become more aware of their data rights, retailers must act like conscientious guardians, providing clear privacy policies and giving consumers control over their data. This approach nurtures trust and assures consumers that their data is being used responsibly.
Navikenz: Enabling AI Transformation in Indian Retail
Navikenz guides Indian retailers through the AI transformation journey. Specializing in AI strategy, data engineering, and automation, Navikenz enables retailers to create seamless, personalized shopping experiences across channels. Its predictive analytics improve decision-making and customer engagement, much like a compass that helps retailers navigate complex market dynamics. With innovations like generative AI and NLP-powered chatbots, Navikenz empowers retailers to enhance customer service and streamline operations, driving growth with tailored solutions. From inventory management to customer engagement, Navikenz provides the tools retailers need to master the art of personalized shopping at scale.
The Future of AI in Indian Retail: Trends to Watch
As the industry evolves, retailers must keep their eyes on the horizon and anticipate the winds of change. Key AI-driven trends that will shape the future of Indian retail include:
Enhanced Personalization Algorithms: Like a seasoned tailor, advanced AI models will understand individual preferences with increasing precision.
Integration of Augmented and Virtual Reality: Retailers will embrace immersive experiences, transforming shopping into an interactive, engaging activity.
Expanded Use of Predictive Analytics: AI-powered insights will guide inventory management, demand forecasting, and even marketing strategies, allowing retailers to stay ahead of consumer needs.
Conclusion: Embracing AI for Long-Term Success
For Indian retailers, adopting AI is no longer a luxury—it’s the key to future success. With Navikenz as a strategic partner, retailers can unlock the full potential of AI, enhancing personalization, streamlining operations, and fostering lasting customer relationships. Responsible AI adoption, like a well-lit path, will help retailers balance personalization with privacy, setting new standards for customer satisfaction and operational excellence. Those who invest in AI today are not just adapting—they’re paving the way for a new era in Indian retail, where customer experiences are richer, smarter, and more meaningful.
Artificial Intelligence (AI) is transforming manufacturing by driving automation, predictive analytics, and real-time data utilization. In today’s competitive landscape, embracing advanced technologies like AI, IoT, and big data analytics is crucial for industries to stay agile, sustainable, and efficient. Just as a skilled conductor orchestrates a symphony, AI orchestrates complex processes within smart manufacturing, creating harmony between technology, machinery, and human expertise. This blog explores how AI is transforming smart manufacturing, key trends shaping the sector, and the challenges manufacturers face. It also highlights how Navikenz, with its expertise in AI-driven solutions, can support businesses on their journey toward digital transformation.
Understanding Smart Manufacturing
Smart manufacturing integrates advanced technologies to create a connected, efficient, and flexible production environment. The foundation is built on interconnectivity and data utilization, enabling machines, devices, and humans to communicate seamlessly through IoT sensors and analytics platforms. Imagine a “digital nervous system” where each sensor, machine, and device acts like a nerve sending real-time information back to the brain (AI systems), ensuring the entire body (the factory) functions optimally.
BMW, in its German manufacturing plants, demonstrates this interconnectivity. By connecting machinery with IoT sensors and implementing AI-driven analytics, BMW achieves real-time monitoring and predictive maintenance, improving both efficiency and product quality.
Key Components of Smart Manufacturing
Interconnectivity: IoT-enabled systems gather real-time data at every production stage to provide actionable insights.
Data Utilization: Big data analytics identify patterns, detect bottlenecks, and predict equipment failures.
Connected Devices and Sensors: These enable real-time monitoring of machine performance, predictive maintenance by forecasting equipment breakdowns, and automated quality control through continuous product inspection.
Smart manufacturing ensures that operations remain adaptive, helping companies address challenges with agility while reducing costs and waste.
The Role of AI in Smart Manufacturing
AI enables automation, optimization, and predictive insights in manufacturing, enhancing traditional processes by shifting from reactive management to proactive operations. This shift ensures higher efficiency and precision.
At Siemens’ Amberg Electronics Factory in Germany, AI-based predictive maintenance reduces downtime and prevents equipment failures. Machines send data continuously to AI models, which predict potential breakdowns before they occur, allowing Siemens to schedule maintenance only when it’s needed, saving both time and cost.
Transforming Processes with AI
Automation: AI-powered systems automate repetitive tasks, freeing human workers for more complex activities.
Optimization: Algorithms adjust parameters in real-time to improve machine performance and resource utilization.
Predictive Capabilities: AI predicts maintenance needs, reducing downtime and minimizing costs.
Key AI Algorithms in Manufacturing
Machine Learning (ML): Identifies patterns in data to improve predictive maintenance and optimize quality control.
Computer Vision: Enables automated defect detection through visual data interpretation.
AI-driven systems promote data-based decision-making, allowing manufacturers to streamline processes, enhance efficiency, and continuously improve operations.
Enhancing Efficiency with Automation and Real-Time Data
Automation in manufacturing enhances speed, accuracy, and adaptability while minimizing human error. AI systems ensure flexible production processes that quickly adapt to changing demands.
At Foxconn, AI and automation are pivotal in assembling Apple products with precision. The automation of repetitive tasks, such as screwing and sorting, minimizes human error and increases productivity, allowing Foxconn to meet high-volume production demands.
Predictive Maintenance
Monitoring Equipment Health: Sensors collect real-time data to identify irregularities.
Data Analysis: Historical data models predict breakdowns in advance.
Real-Time Monitoring: AI systems detect defects and trigger immediate corrective actions.
Trend Analysis: Quality data helps identify patterns for continuous process improvement.
Big data analytics further enhances overall equipment effectiveness (OEE) by identifying bottlenecks and ensuring smooth production.
Collaborative Robotics: Bridging the Human-Machine Gap
Collaborative robots, or cobots, work alongside human operators to improve productivity by sharing tasks. Cobots handle repetitive or precision-intensive operations, while human workers focus on more complex roles.
Increased Productivity: Cobots operate continuously without fatigue, enhancing production speed and accuracy.
Workforce Training: Manufacturers provide training to ensure safe and effective collaboration between workers and cobots.
In Ford’s Michigan assembly line, cobots handle intricate and repetitive tasks like tightening bolts, while skilled human workers perform tasks requiring dexterity and problem-solving skills. This collaboration enhances productivity and maintains quality standards.
This synergy between humans and machines prepares the workforce for a future where automation plays an increasingly significant role.
Sustainability in Smart Manufacturing
Sustainability is a priority for manufacturers, with AI and IoT driving environmentally friendly practices. Circular supply chains that prioritize recycling and resource efficiency are essential to minimize environmental impact and reduce costs.
Supporting Technologies for Sustainability
Smart Energy Management: AI identifies opportunities to reduce energy consumption and waste.
High-Performance Materials: Innovations in materials science improve recyclability and reduce carbon emissions.
Unilever’s AI-driven smart manufacturing initiatives, such as using digital twins, allow the company to monitor energy usage in real-time and optimize consumption patterns across plants worldwide, helping meet ambitious sustainability targets.
Integrating AI into manufacturing aligns operations with sustainability goals, giving companies a competitive edge in global markets.
AI-Powered Supply Chain Optimization
Traditional supply chains often struggle with limited visibility, inflexibility, and resilience issues. AI addresses these challenges by providing advanced analytics and real-time monitoring to improve decision-making and agility.
Advanced Analytics: AI models forecast demand and optimize inventory levels.
Enhanced Visibility: Digital twins offer real-time tracking and monitoring of supply chain activities.
Improved Resilience: AI identifies potential risks and suggests contingency plans to mitigate disruptions.
DHL uses AI and digital twins to manage its complex logistics operations. This approach provides real-time visibility across their supply chain, optimizing routes, predicting demand, and minimizing waste, ensuring resilient operations even during global disruptions.
AI-powered supply chains ensure consistent and efficient operations, helping businesses adapt quickly to changing market dynamics.
Overcoming Barriers to AI Adoption in Manufacturing
Despite the numerous benefits, adopting AI in manufacturing presents challenges, including legacy systems, skill gaps, and data security concerns.
Strategies for Successful AI Adoption
Investing in Workforce Development: Training programs and partnerships with academic institutions help upskill employees in AI technologies.
Upgrading Infrastructure: Gradual upgrades of legacy systems ensure smooth integration with AI platforms.
Enhancing Data Security: Robust encryption and access controls protect sensitive manufacturing data.
Addressing these challenges strategically ensures a seamless transition toward AI-powered operations.
Navikenz: Driving AI-Enabled Transformation
Navikenz brings deep expertise in AI strategy, digital engineering, and data solutions, supporting businesses through every stage of their transformation journey. Here’s how Navikenz adds value to manufacturing operations:
AI/ML Solution Development: Customized AI solutions for predictive maintenance and process optimization.
MLOps Frameworks: Efficiently managing scalable AI deployments.
Cloud Engineering and FinOps: Facilitating cloud migrations and optimizing costs with FinOps strategies.
Data Strategy and Visualization: Expertise in data engineering ensures actionable insights from real-time data, with visualization tools empowering data-driven decision-making.
Sustainability Consulting: Navikenz guides companies in adopting sustainable practices by integrating AI and IoT for energy efficiency.
End-to-End AI Governance: From identifying use cases to AI implementation, Navikenz ensures alignment with business goals for measurable outcomes.
Conclusion
In an evolving landscape, AI-driven smart manufacturing offers unparalleled opportunities for growth, efficiency, and sustainability. Organizations must embrace innovation to remain competitive by adopting AI, automation, predictive analytics, and collaborative robotics.
With Navikenz as a strategic partner, businesses are well-equipped to navigate the challenges of digital transformation, building future- ready operations that enhance productivity and sustainability. Together, we can harness the full capabilities of AI-powered manufacturing to ensure long-term success and competitive advantage in India’s growing industrial landscape.
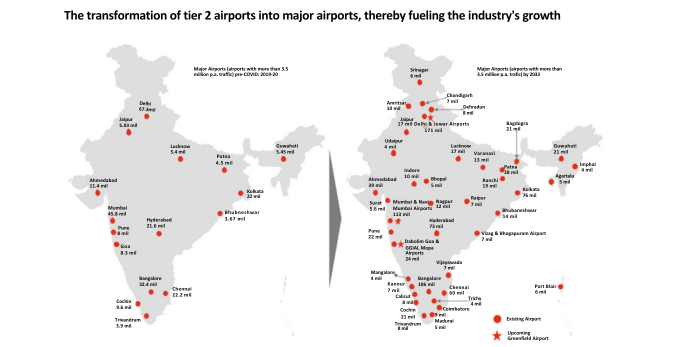
Airports are rapidly evolving into key centers for multi-modal travel across cities and countries. The surge in passenger volumes, increased flight frequency, and expanding connections to new destinations across India and Asia are driving the expansion of airports and their services.
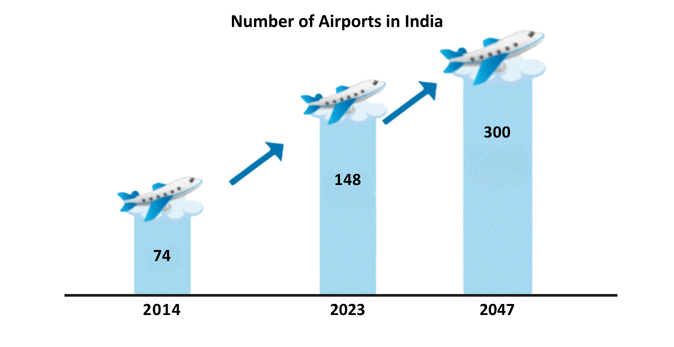
India, already the world’s 3rd largest civil aviation market, plans to double the number of operational airports to 300 by 2047, driven by an eightfold rise in passenger traffic.
India is set to see investments worth US$ 25 billion by 2027, with Indian carriers projected to double their fleet capacity to around 1,100 aircraft by that year.
The scale and diversity of facilities provided at airports significantly influence the travel experience of passengers worldwide. This presents a unique opportunity for airport operators to attract, engage, build loyalty, and generate a steady stream of revenue from travelers.
Changing demographics and digital-first lifestyle
India’s changing demographics and the rise of a digital-first lifestyle, fueled by affordable communication devices, are reshaping how travelers interact with service providers.
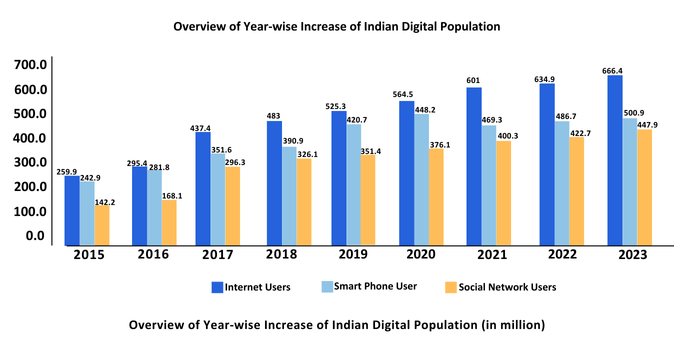
According to recent statistics, India had over 700 million internet users in 2023, and this number is expected to surpass 900 million by 2025. Moreover, smartphone penetration has been a key enabler, with more than 80% of internet traffic in India coming from mobile devices.
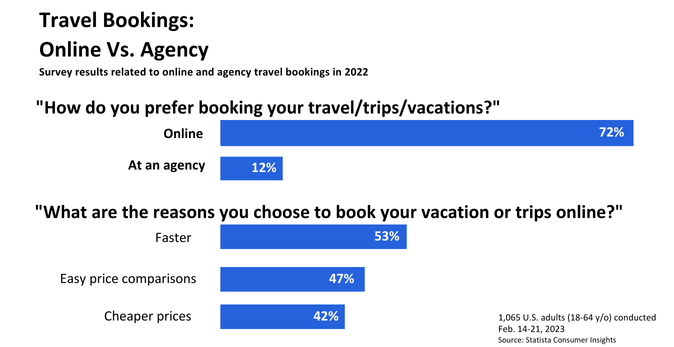
This shift is significantly influencing the way travelers engage with service providers. Travel Commerce Insights Report 2022 highlights that 74% of urban travelers in India prefer to make their travel bookings and queries through digital platforms, including websites, apps, and social media, rather than traditional methods like visiting travel agencies. Furthermore, instant messaging apps like WhatsApp are becoming popular for customer service interactions, with India having the largest number of WhatsApp users in the world—over 500 million active users.
The Indian middle class is expanding, bringing millions of new passengers into the aviation fold. These passengers prioritize affordability but are increasingly looking for a superior travel experience — from the airport to in-flight services. With regional connectivity schemes like UDAN, people from Tier 2 and Tier 3 cities now form a significant portion of this demographic. As these cities become aviation hubs, their unique needs such as improved language support, real-time local information, and streamlined check-in processes must also be addressed.
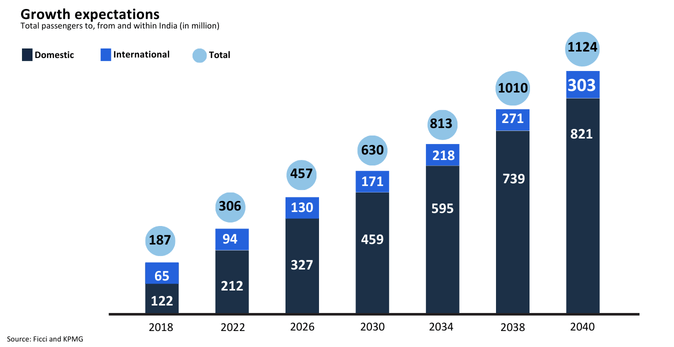
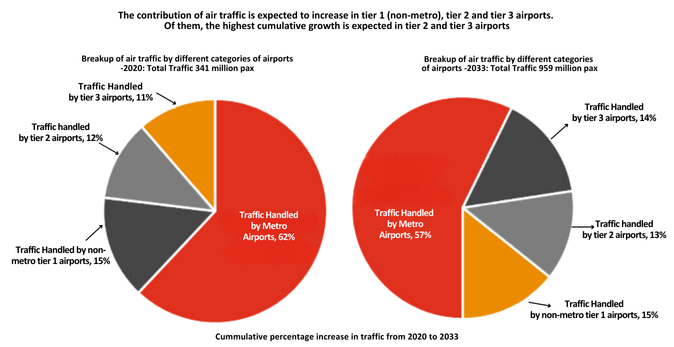
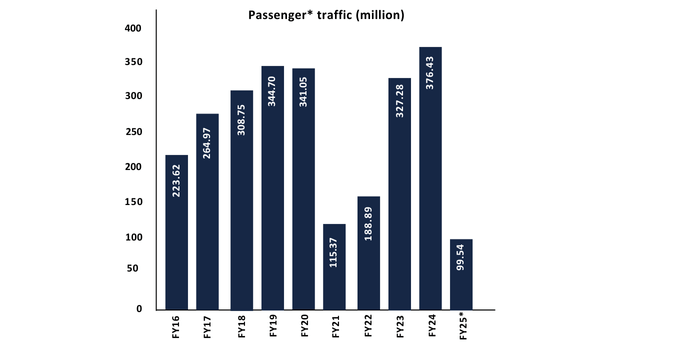
Passenger traffic is projected to increase from 376 million to 3-3.5 billion annually by 2047, with international traffic constituting 10-12% of this growth(Aviation Industry Report). India is expected to witness investments worth US$ 25 billion by 2027, with Indian carriers doubling their fleet capacity to around 1,100 aircraft by that year.
Travelers’ expectations: A personalized, always-on experience
The quality, perception, and reputation of services are heavily influenced by providers’ agility and consistency in responding to customer needs. Passengers now reach out via multiple channels including voice calls, chat windows, emails, social media posts, instant messaging, and browsing through websites and mobile apps. They expect responses that are instant, personalized, contextual, and actionable.
According to a report by McKinsey, 75% of customers expect service providers to deliver immediate responses. A study by The Aberdeen Group has shown that even a 1-second delay in response time can lead to 16% lower customer satisfaction and significantly reduce loyalty, potentially causing businesses to lose their existing customers.
Challenges for airport operators and service providers
This explosive growth in passenger numbers comes with its own set of challenges for airports and airlines.
Scalability: Airports are struggling to keep pace with the growing passenger volume. With plans to increase the number of airports to 300 by 2047, there is a pressing need for infrastructure upgrades, capacity expansions, and enhanced services to prevent congestion.
Customer experience: As more passengers take to the skies, delivering a consistently high-quality experience is becoming challenging. Travelers expect prompt communication, easy access to information, and instant problem resolution. Handling multiple channels of communication (calls, emails, social media, chatbots) while ensuring seamless interaction requires cutting-edge solutions.
Personalization: Travelers today expect personalized interactions, from receiving the right promotions to receiving timely alerts about their travel plans. However, the sheer scale of data generated from millions of passengers presents a challenge in curating personalized experiences.
Diverse expectations: With the broadening demographic of travelers, the aviation industry needs to cater to varied preferences, ranging from budget-conscious travelers to those seeking premium services. Providing this wide spectrum of service offerings efficiently can be difficult.
A one-size-fits-all approach is ineffective for today’s travelers. Airport operators and service providers must prioritize developing a comprehensive strategy and investing in future-proof technology infrastructure to effectively communicate, interact, and engage with their expanding customer base
With India aiming to operationalize 12 new airports this year under the UDAN scheme, conventional solutions such as call centers, IVR services, and customer service desks will struggle to scale with increasing requests(Aviation Industry Report). Airports must seize the opportunity to attract and retain travelers by offering innovative, high-quality services. These improvements could drive long-term loyalty and consistent revenue streams.
Enter generative AI, a technology that has the potential to completely transform the real-time customer service provided by airports turning the customer experience from one that is reactive to one that is proactive.
Generative AI: The secret weapon for seamless service
Generative AI is rapidly emerging as a key solution to these challenges, shaping the future of air travel. By 2025, Gartner predicts that 40% of customer service organizations will adopt AI-powered tools to enhance capabilities and improve interactions. These AI tools can handle thousands of requests simultaneously, providing instant, contextual, and personalized responses. This reduces wait times, improves customer satisfaction and significantly reduces operational costs. The agility and scalability of Generative AI make it a vital component of future strategies for airport operators looking to enhance customer experiences while maintaining efficiency
The role of Generative AI in addressing these challenges
Generative AI can help service providers ingest, process, and analyze large volumes of text, images, audio, video, and multimedia content to extract relevant intelligence and guide business actions.
Here’s how Generative AI can help:
Customer interaction and support: AI-powered chatbots and virtual assistants can instantly provide travelers with relevant, contextual information — from flight updates to baggage information and visa requirements. These systems can manage inquiries 24/7 across multiple channels, easing the burden on customer service teams and ensuring timely responses.
Data-driven personalization: By analyzing traveler behavior, preferences, and history, Generative AI can offer personalized recommendations, such as travel itineraries, seat preferences, or in-flight services. This not only improves customer satisfaction but also opens up new revenue streams for airlines and airports through targeted marketing.
Operational efficiency: AI can help airports and airlines optimize operations by predicting passenger traffic patterns, managing check-in queues, and reducing delays. By analyzing historical data and real-time inputs, AI can guide airport authorities on resource allocation, improving overall efficiency.
Multilingual support: With India’s linguistic diversity, Generative AI can offer translation services and multi-language support, making travel more accessible to non-English speakers, especially from Tier 2 and Tier 3 cities.
Proactive problem resolution: AI-driven systems can anticipate potential issues, such as flight delays or baggage mishandling, and notify travelers proactively. This builds trust and ensures a smoother experience for passengers.
Digital identity: A passport-free future?
Digital identification is a significant AI-driven innovation currently under development. Imagine a time when travellers won’t have to worry about losing their passports, boarding cards, or security checks. Rather, their digital identity—confirmed by AI-driven systems—would let them go from check-in to boarding with ease. Airports utilising AI and biometric data to produce smooth, safe travel experiences may become the standard by 2030.
By investing in advanced technologies such as Generative AI for customer service and facial recognition for security, airports can significantly enhance both the efficiency and personalization of the travel experience, setting the stage for the next generation of smart, connected travel hubs. These airports will be better equipped to handle the growing number of travellers, guarantee smooth transit, and eventually foster enduring consumer loyalty. It takes more than just scaling for growth to stay ahead in a sector that is changing quickly.
The road ahead: A new era of travel
As India continues to invest in its aviation infrastructure, the integration of advanced technologies like Generative AI will be pivotal in addressing the sector’s challenges. The increasing passenger traffic will demand scalable solutions, and AI has the potential to automate and enhance multiple aspects of the travel journey — from ticket booking and check-ins to security protocols and customer engagement.
At Navikenz, we assist global businesses in designing and deploying scalable technology platforms enabled with Generative AI capabilities. We support travel service providers, including online travel agencies, immigration services, hospitality providers, and airport operators, with solutions that allow customers to access the right information through their preferred channels.
Our expertise stems from our extensive experience in serving the global travel industry, including airlines, airports, travel technology providers, hotels, car rental agencies, train services, and online travel agencies.
Our Generative AI-enabled solutions for the Travel industry
NKQuire™: A multi-lingual, intelligent conversational chatbot (RAG-enabled) that helps customers query and find the most accurate answers.
NaviCADE™: A solution that processes business contracts and agreements, enabling businesses to track and manage contractual obligations and legal risks.
NVISION™: A scalable, image-based human identity detection and matching solution for enhanced security at airports.
NectarBOT™: A tool that ingests, processes, and analyzes information from files, emails, and social media feeds, using various Large Language Models (LLMs) to generate relevant answers for travelers’ queries.
Partnership opportunities
As the Indian aviation sector continues to grow and evolve, embracing AI-driven innovations will be key to enhancing customer experiences, boosting operational efficiencies, and sustaining growth in this dynamic market
We welcome the opportunity to collaborate and discuss your business priorities in delivering memorable experiences for your customers. With our expertise and advanced Generative AI solutions, we can help identify and implement the right technology solutions to meet your business goals.
By focusing on scalable solutions today, you’re preparing for the passengers—and the challenges—of tomorrow.Curious to see how AI can transform your operations? Explore more about our suite of solutions, including NKQuire, NaviCADE, NVISION, and NectarBOT, by clicking here.
“Alexa, what is a chatbot? Explain in French.”
Alexa hit the market on November 6, 2014. That’s right—10 years ago, it seamlessly integrated into our daily lives. But have we ever considered why and how this life-simplifying technology, called the “Chatbot” or “Chatterbot” as it was originally known, came into existence? Let’s take a closer look.
History
The term “Chatbot” was coined in 1994 by Michael Loren Mauldin, who also attempted to create one. A basic chatbot is essentially a program of 50 to 100 lines of code. These seemingly simple lines of code took the industry by storm in 2022 when ChatGPT was launched, marking the first time an AI language model of such scale and capability became widely accessible to the public. This revolutionary development in how we interact with AI comes decades after the first chatbot, ELIZA, was developed in 1966!
As the world becomes increasingly interconnected, the need for communication across language barriers has never been more pressing. According to Ethnologue, there are over 7,000 languages spoken worldwide! To overcome these barriers, a revolutionary advancement in the field of artificial intelligence has allowed businesses and individuals to interact seamlessly across different languages. This advancement is known as Multilingual Chatbots.
Use Cases
With 72.4% of consumers preferring to make a purchase in their native language (Common Sense Advisory), multilingual chatbots were designed to understand and respond in multiple languages, making them invaluable tools in a globalized economy. Whether you’re a customer in Tokyo needing support from a company based in New York, or a traveler in Paris looking for restaurant recommendations from an app based in Sydney, multilingual chatbots are there to bridge the gap.
From AirAsia’s AVA to Mastercard’s KAI, L’Oréal’s Mya, and even Alexa, 53% of companies use AI-driven chatbots, according to a Gartner survey. Multilingual chatbots make it easier for companies to provide consistent, high-quality customer service, regardless of the language spoken by their customers. This not only enhances customer satisfaction but also opens up new markets that were previously inaccessible.
The $24.10 billion industry of AI in Natural Language Processing (NLP) (Fortune Business Insights) serves as the core of multilingual chatbot technology. This technology enables chatbots to understand and generate human language in various linguistic contexts. When a user types a query in one language, the chatbot processes the input, determines the intent, and responds appropriately in the same language—or even switches to another language if necessary.
Challenges
Why is the adoption rate still low? The answer lies in the challenges of development:
Accurate Language Understanding: Ensuring that chatbots can accurately understand and respond to diverse linguistic inputs requires extensive training data in multiple languages, as well as ongoing fine-tuning to handle regional dialects, slang, and context-specific phrases.
Cultural Sensitivity: Chatbots need to account not only for language but also for cultural nuances, idiomatic expressions, and user preferences in different regions. Direct translation may not be enough—localizing content and adjusting for cultural sensitivity is essential to avoid misunderstandings or offending users.
Consistency in Quality: Maintaining consistent response quality across different languages can be challenging. A chatbot that performs well in English might struggle with languages that have less training data or more complex grammatical structures.
Conclusion
In the coming years, multilingual chatbots will likely become an integral part of many industries, from customer service and healthcare to education and entertainment. By breaking down language barriers, these chatbots will help create a more connected and inclusive world where information and services are accessible to everyone, regardless of their language. They will play a crucial role in shaping the future of human-AI interaction
Introduction
Artificial Intelligence (AI) is increasingly becoming a cornerstone in efforts to tackle some of the most pressing environmental challenges of our time. From combating climate change to enhancing sustainable agriculture, AI’s ability to process vast amounts of data and generate actionable insights is transforming how we understand and interact with our environment. This article explores various ways AI is being deployed to support environmental sustainability, detailing the innovations and impacts across multiple sectors.
AI and Wildlife Conservation
Artificial Intelligence (AI) is transforming wildlife conservation efforts by enabling scientists to track and monitor animal populations with unprecedented precision. AI’s ability to process vast amounts of data quickly and accurately is a game-changer in identifying, monitoring, and protecting endangered species and their habitats. Let’s explore how AI is making significant strides in wildlife conservation, supported by compelling examples.
AI-powered drones and satellite imagery are crucial tools in monitoring animal habitats and migration patterns. These technologies can also detect illegal activities like poaching, providing critical data that allows conservationists to make informed decisions. For instance, AI models analyze data from various sources, creating comprehensive monitoring systems that offer real-time insights into wildlife activities.
Examples:
Pytorch-Wildlife by Microsoft: This open-source AI model enhances biodiversity monitoring by automating the analysis of data from camera traps and drones. It has been successfully used to monitor opossums in the Galápagos and various animal species in the Amazon Rainforest.
Government-funded AI project in Australia: This initiative focuses on identifying and protecting rare and threatened species. By developing models that recognize and monitor these species, the project provides essential data to help conservationists implement effective strategies.
Citizen Science Initiatives: Projects like eBird from the Cornell Lab of Ornithology use AI to analyze bird sightings shared by the public, creating a global bird distribution database that aids researchers in conservation efforts.
AI in Climate Change Research
Climate change is an undeniable global challenge, but thanks to AI, we have a powerful tool to understand and combat its impacts. By analyzing vast amounts of climate data, AI algorithms uncover valuable insights into historical patterns and real-time measurements. This enables us to identify trends and project future scenarios with greater accuracy, ultimately enhancing our ability to anticipate and address the challenges of climate change.
Leveraging AI’s predictive capabilities, we can develop targeted strategies to mitigate the worst effects of climate change. From reducing greenhouse gas emissions to adopting renewable energy sources, AI empowers us to make informed decisions that lead to a more sustainable future. Moreover, AI can optimize energy systems and infrastructure, improving efficiency and minimizing waste. Integrating AI technologies into smart grids, energy management systems, and transportation networks allows us to achieve greater sustainability and resilience.
In the next five to 10 years, AI’s ability to analyze climate data and make accurate predictions will be instrumental in our fight against climate change.
Examples:
Emissions Reduction: Google’s DeepMind AI has optimized energy use in data centers, cutting cooling energy consumption by 40%, demonstrating significant emission reductions in energy-intensive sectors.
Boosting Renewable Energy: Siemens uses AI to predict wind turbine performance, ensuring maximum energy output and minimal downtime, pushing us closer to a sustainable energy future.
Smart Grids: In Singapore, AI systems manage energy distribution efficiently, reducing waste and ensuring that renewable energy is utilized to its full potential.
Sustainable Agriculture with AI
Feeding the growing global population while minimizing the environmental impact is a pressing concern. Luckily, AI is revolutionizing the field of sustainable agriculture. By combining AI algorithms with data from soil sensors, drones, and weather stations, farmers can optimize crop yields while reducing the use of water, fertilizers, and pesticides.
AI-powered systems can provide real-time insights on crop health, pest detection, and irrigation needs. This enables farmers to make data-driven decisions, resulting in higher productivity, reduced waste, and a more sustainable agricultural industry.
Let’s explore some examples of how AI is transforming agriculture practices towards a more sustainable future:
AI enables precision farming techniques that optimize resource allocation and reduce waste.
AI algorithms analyse data from soil sensors, drones, and satellites to provide real-time insights on crop health, moisture levels, and pest infestations.
AI predicts optimal planting times, crop varieties, and nutrient requirements to maximize yields and minimize chemical inputs.
AI-powered systems detect and monitor pests and diseases, allowing for targeted interventions and reduced reliance on chemical pesticides.
Automation driven by AI improves farming operations, increasing efficiency and reducing resource consumption.
AI for Clean Energy
Transitioning to clean and renewable energy sources is vital for combating climate change. AI is accelerating this transition by improving the efficiency of renewable energy systems. For instance, AI algorithms can optimize the output of solar panels by adjusting their angles based on weather conditions and energy demand.
Furthermore, AI is driving breakthroughs in energy storage technology, enabling better management of intermittent energy sources like wind and solar. By utilizing AI, we can achieve a more reliable and cost-effective clean energy infrastructure, reducing our reliance on fossil fuels and mitigating climate change.
How AI is making renewable energy greener?
Optimal Energy Generation: AI algorithms optimize renewable energy generation by analysing weather patterns, energy demand, and grid conditions, allowing for more efficient utilization of solar, wind, and other renewable sources.
Energy Grid Management: AI helps manage energy grids by predicting demand fluctuations, optimizing energy distribution, and balancing supply and demand in real-time, reducing waste and improving overall grid efficiency.
Predictive Maintenance: AI algorithms analyze data from sensors and equipment to predict and prevent failures in renewable energy systems. This proactive maintenance approach minimizes downtime, improves performance, and reduces the need for costly repairs.
Energy Storage Optimization: AI optimizes the charging and discharging of energy storage systems, such as batteries, based on electricity prices, demand patterns, and renewable energy availability. This maximizes the use of stored energy and improves grid stability.
Smart Energy Consumption: AI-enabled smart home systems analyse energy usage patterns and make automated adjustments to optimize energy consumption. This includes managing energy-intensive appliances, adjusting lighting and temperature settings, and integrating with renewable energy sources for efficient utilization.
AI in Waste Management
The proper management of waste is a significant challenge in achieving a sustainable future. Fortunately, AI is making great strides in waste management systems. AI-powered robots can sort recyclable materials from mixed waste with impressive accuracy, improving recycling rates and reducing landfill usage.
Additionally, AI algorithms can optimize waste collection routes, minimizing fuel consumption and greenhouse gas emissions. By leveraging AI, we can create smarter waste management systems that promote recycling, reduce pollution, and contribute to a cleaner environment.
“In conclusion, with AI as our ally, we can lead the charge in preserving and nurturing our precious planet”
In a world where environmental conservation is crucial, AI emerges as a powerful ally in the quest for a greener future. Eco-Intelligence paves the way for sustainable practices, impacting wildlife conservation, climate change research, sustainable agriculture, clean energy, and waste management. AI enables tracking endangered species, predicting climate change effects, optimizing farming resources, accelerating clean energy adoption, and revolutionizing waste management. Embracing AI’s potential requires responsible and ethical implementation to ensure it remains a force for positive change. By exploring AI’s possibilities and addressing challenges, AI can lead the charge in combating climate change, protecting biodiversity, and creating a sustainable future for generations to come.
Imagine a world where your favourite actor delivers a stunning performance in a movie they never actually filmed, or a bank executive authorizes a massive transfer they’ve never heard of. This world isn’t a scene from a sci-fi movie-it’s our current reality. The rise of deep fake technology opens the door to alarming possibilities. I am sure you must have come across at least one of the examples stated below which were in recent news –
Scarlett Johansson’s Voice by OpenAI: Recently, OpenAI demonstrated a deep fake of Scarlett Johansson’s voice. While it raised eyebrows, it also highlighted the potential for voice cloning in dubbing films, creating virtual assistants with celebrity voices, and personalizing customer experiences. However, it’s worth noting that Scarlett Johansson expressed deep concern and displeasure regarding this unauthorized use of her voice.
Mark Zuckerberg Deepfake by British Artists: Two British artists created a deepfake video of Facebook CEO Mark Zuckerberg, in which he appeared to talk to CBS News about the “truth of Facebook and who really owns the future.” This video was widely circulated on Instagram and went viral.
University of Washington’s Deepfake of President Barack Obama: Researchers at the University of Washington posted a deepfake of President Barack Obama, making him say whatever they wanted. This demonstrated the potential for misuse, showing how such technology could create a threat to world security by making fake communications appear real.
Let’s go back to drawing board & understand more. And understand what kind of misuse is happening specific to BFSI industry.
What Are Deep Fakes?
Deep fakes, a blend of “deep learning” and “fake,” use artificial intelligence to create highly realistic but fabricated audio, video, and images. These manipulations can make people appear to say or do things they never did, leading to both fascinating and frightening scenarios. The creation process involves collecting high-quality data of the target person, training AI models like Generative Adversarial Networks (GANs) on this data, fine-tuning the generated content to match the target’s specific features and mannerisms, and rendering the final polished video or audio, making it nearly indistinguishable from genuine recordings.
Deep fakes use artificial intelligence to create highly realistic but fabricated audio, video, and images. While the technology has potential applications in the entertainment industry, such as resurrecting legendary actors for new movies or dubbing films in multiple languages, it raises significant ethical and security concerns. The misuse of deep fakes can lead to serious consequences, such as spreading misinformation, violating privacy, and undermining trust.
Deep Fakes and BFSI Frauds: A Growing Concern
While the creative world sees an array of opportunities, the BFSI sector is on high alert. Deep fakes pose significant threats, from identity theft to elaborate scams. Here’s how:
Voice Phishing Scams: Scammers can use deep fakes to clone the voices of CEOs or other executives, instructing employees to transfer funds or share sensitive information. One notable case involved a UK-based energy firm’s CEO who was tricked into transferring €220,000 after receiving a deep fake call mimicking his boss’s voice.
KYC Fraud: The emergence of deepfake technology poses a significant concern for KYC measures, potentially making current verification systems obsolete. As AI-generated deepfakes become increasingly indistinguishable from genuine identities, the vulnerability of KYC processes to fraudulent manipulation increases, necessitating proactive strategies to safeguard against evolving threats.
Video Fraud: Imagine receiving a video call from a supposed bank manager, instructing you to follow certain steps to secure your account. With deep fakes, these scenarios are no longer far-fetched.
In India, a deep fake video featuring a prominent politician was circulated, misleading the public and causing significant unrest. This incident underscores the potential for deep fakes to manipulate public perception and cause widespread disruption.
How to Stop Malicious Deep Fakes
Stopping malicious deep fakes requires a multifaceted approach, combining technology, policy, and public awareness. Here are some strategies:
Technological Solutions
Detection Algorithms: Developing and deploying AI models that can detect the subtle inconsistencies in deep fakes. These algorithms analyse elements like lighting, shadows, and facial movements that are difficult for deep fakes to replicate perfectly.
Blockchain Technology: Using blockchain to verify the authenticity of media. Each piece of content can be tagged with a digital signature that verifies its source and integrity, making it harder for fake content to be passed off as genuine.
Regulatory Measures
Legal Frameworks: Governments need to establish clear laws and regulations addressing the creation and dissemination of deep fakes. This includes penalties for malicious use and protections for victims.
Platform Policies: Social media and content-sharing platforms must implement stringent policies to detect and remove deep fake content. Collaborating with AI developers can enhance these platforms’ ability to spot fakes quickly.
Public Awareness
Education Campaigns: Public awareness campaigns can help individuals understand the risks associated with deep fakes and learn how to spot them. This includes recognizing signs like unnatural facial movements, inconsistent lighting, and audio-visual mismatches.
Media Literacy: Enhancing media literacy so that people can critically evaluate the content they consume. This includes understanding how deep fakes are made and recognizing potential motives behind their creation.
Deep Fakes and Security Risks
As deep fakes become more advanced, it’s crucial to balance their potential for innovation with the need for security. In sectors such as BFSI, they pose a significant risk. Strong measures are necessary to combat this threat. Without them, the consequences could be severe. Prioritizing security over innovation is essential to protect against the dangers of deep fakes.
The Future of Deep Fakes
The future of deep fakes is alarming. While they can be used for creative and educational purposes, the risks to security and privacy are significant. Deep fakes can be weaponized to spread misinformation, manipulate public opinion, and commit fraud, making them a serious threat that cannot be ignored.
As a software leader navigating the AI revolution, you’re likely familiar with the dread that accompanies the technical debt monster. Fueled by the rush to adopt cutting-edge AI tools and technologies, this insatiable beast can wreak havoc on your codebase, slowing progress and putting your entire operation at risk.
As organizations increasingly adopt AI to enhance their operations, the risk of accumulating technical debt escalates. This phenomenon occurs when the quick adoption of AI technologies compromises system design or coding practices, potentially resulting in future complications and costs. Understanding the nuances of technical debt is essential to avoid the pitfalls associated with rapid AI integration and ensure sustainable technological advancement.
Understanding Technical Debt
Consider the scenario of constructing a house but opting to forgo deep foundations in favor of expediency. While it may suffice momentarily, technical debt in the technology sphere arises when teams choose the path of least resistance to expedite product delivery, inevitably leading to potential complications in subsequent stages due to the shortcuts taken during the initial phases of AI integration.
Over time, technical debt can impede development speed, increase the likelihood of bugs and errors, and hinder the ability to adapt to changing requirements. Just like financial debt, technical debt must be repaid eventually, either through refactoring, rewriting code, or addressing underlying issues, to ensure the long-term health and sustainability of the software.
AI and the Rise of Technical Debt
The integration of AI into software products is a prime scenario for accruing technical debt. Rapid deployment of AI models, under pressure to meet market demands, often means that long-term consequences of design choices are overlooked. AI systems are particularly prone to this because they require continuous updates and maintenance to stay effective as new data comes in or when operating conditions change.
For instance, Uber’s self-driving car program accumulated significant technical debt due to the rush to deploy ahead of competitors, leading to a fatal accident in 2018. Key issues included a lack of rigorous testing, outdated sensor data, insufficient redundancies, inadequate monitoring, and inherited technical debt from acquisitions. The mounting technical debt resulted in a system unable to reliably detect pedestrians, forcing Uber to suspend the program and re-evaluate its autonomous vehicle development approach, highlighting the severe risks of prioritizing rapid AI deployment over safety and maintainability.
AI as a Debt Reducer
Ironically, the technology that often contributes to technical debt can also provide solutions to manage it. AI can be used to identify inefficiencies and predict where issues are most likely to occur, allowing companies to proactively manage potential debts before they become unmanageable.
Automated code refactoring tools powered by AI can analyze and optimize code more efficiently than manual processes, significantly reducing the burden of technical debt.
Predictive analytics can forecast potential future problems in the system, allowing teams to address these issues proactively.
Examples of Destructive Technical Debt in Real-World Scenarios
Royal Mail Ransomware Attack: In January 2023, Royal Mail in the UK suffered a ransomware attack that disrupted international deliveries. The attackers used the LockBit ransomware, which not only encrypted data on the servers but also potentially exfiltrated it, leveraging technical vulnerabilities possibly exacerbated by technical debt within Royal Mail’s IT infrastructure.
Air Europa Data Breach: In October 2023, Air Europa disclosed a data breach involving the theft of sensitive financial information of its customers, including card numbers and CVV codes. The breach underscores the risks associated with technical debt, particularly in terms of outdated or inadequately protected data storage and transfer systems.
So, how can you prevent technical debt from overwhelming your software development process? Here’s a streamlined strategy to keep it under control.
Embrace Regular Code Reviews: Incorporate routine code reviews to catch potential technical debt early. This practice not only upholds coding standards but also enhances code quality, motivating developers to produce cleaner code in anticipation of reviews.
Systematic Refactoring: Dedicate time regularly for refactoring to improve your codebase’s structure. This makes it easier to maintain and expand.
Track and Prioritize: Employ tools like Jira or GitHub Issues to log and keep tabs on technical debt. Focus on addressing the most critical issues first to make efficient use of your resources.
By adopting these strategies, companies can manage technical debt effectively, ensuring it doesn’t hinder your project’s long-term success.
Effectively managing technical debt—especially in the fast-evolving field of AI—requires a proactive and disciplined approach. By prioritizing regular code reviews, engaging in systematic refactoring, and rigorously tracking and prioritizing issues, organizations can mitigate risks and foster long-term sustainability. The examples discussed illustrate the severe impacts of neglecting technical debt, highlighting the necessity of vigilant management to safeguard the integrity and progress of technological initiatives.
This website uses cookies to ensure you get the best experience on our website