
Entity Extraction using LLMs for Smarter Data Insights

Marseelan A
Principal Data Scientist
Introduction
Large Language Models have taken the AI community by storm. Every day, we encounter stories about new releases of Large Language Models (LLMs) of different types, sizes, the problems they solve, and their performance benchmarks on various tasks. The typical scenarios that have been discussed include content generation, summarization, question answering, chatbots, and more.
We believe that LLMs possess much greater Natural Language Processing (NLP) capabilities, and their adaptability to different domains makes them an attractive option to explore a wider range of applications. Among the many NLP tasks they can be employed for, one area that has received less attention is Named Entity Recognition (NER) and Extraction. Entity Extraction has broader applicability in document-intensive workflows, particularly in fields such as Pharmacovigilance, Invoice Processing, Insurance Underwriting, and Contract Management.
In this blog, we delve into the utilization of Large Language Models in contract analysis, a critical aspect of contract management. We explore the scope of Named Entity Recognition and how contract extraction differs when using LLMs with prompts compared to traditional methods. Furthermore, we introduce NaviCADE, our in-house solution harnessing the power of LLMs to perform advanced contract analysis.
Named Entity Recognition
Named Entity Recognition is an NLP task that identifies entities present in text documents. General entity recognizers perform well in detecting entities such as Person, Organization, Place, Event, etc. However, their usage in specialized domains such as healthcare, contracts, insurance, etc. is limited. This limitation can be circumvented by choosing the right datasets, curating data, customizing models, and deploying them.
Customizing Models
The classical approach to models involves collecting a corpus of domain-specific data, such as contracts and agreements, manually labeling the corpus, and training it with robust hardware infrastructure, benchmarking the results. While people have found success with this approach using SpaCy or BERT-based embeddings to fine-tune models, the manual labeling effort and training costs involved are high. Moreover, these models do not have the capability to detect entities that were not present in the training data. Additionally, the classical approach is ineffective in scenarios with limited or no data.
The emergence of LLMs has brought about a paradigm shift in the way models are conceptualized, trained, and used. A Large Language Model is essentially a few-shot learner and a multi-task learner. Data scientists only need to present a few demonstrations of how entities have been extracted using well-designed prompts. Large language models leverage these samples, perform in-context learning, and generate the desired output. They are remarkably flexible and adaptable to new domains with minimal demonstrations, significantly expanding the applicability of the solution's extraction capabilities across various contexts. The following section describes a scenario where LLMs were employed.
Contract Extraction Using LLM
Compliance management is a pivotal component of contract management, ensuring that all parties adhere to the terms, conditions, payment schedules, deliveries, and other obligations outlined in the contracts. Efficiently extracting key obligations from documents and storing them in a database is crucial for maximizing value. The current extraction process is a combination of manual and semi-automated methods, yielding mixed results. Improved extraction techniques have been used by NaviCADE to deliver significantly better results.
NaviCADE
NaviCADE is a one-stop solution for all data extraction from documents. It is built on cloud services such as AWS to process documents of different types coming from various business functions and industries. NaviCADE has been equipped with LLM capabilities by selecting and fine-tuning the right models for the right purposes. These capabilities have enabled us to approach the extraction task using well-designed prompts comprising of instruction, context, and few-shot learning methods. NaviCADE can process different types of contracts, such as Intellectual Property, Master Services Agreement, Marketing Agreement, etc.
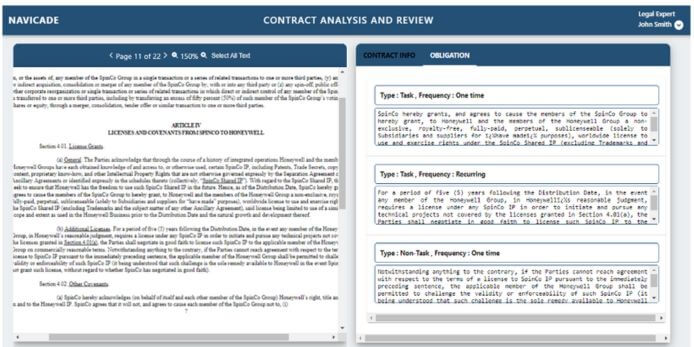
A view of the NaviCADE application is attached below, displaying contracts and the extracted obligations from key sections of a document. Additionally, NaviCADE provides insights into the type and frequency of these obligations.
In Conclusion
Large Language Models (LLMs) have ushered in a new era of Named Entity Recognition and Extraction, with applications extending beyond conventional domains. NaviCADE, our innovative solution, showcases the power of LLMs in contract analysis and data extraction, offering a versatile tool for industries reliant on meticulous document processing. With NaviCADE, we embrace the evolving landscape of AI and NLP, envisioning a future where complex documents yield valuable insights effortlessly, revolutionizing compliance, efficiency, and accuracy in diverse sectors.