
Automation in Pharmacovigilance: Optimizing Drug Safety

Balaji Krishnan
Chief of Customer Success
Pharmacovigilance is increasingly dealing with a variety of rapid technology, regulatory, environment and business changes. The safety and efficacy of medications remain a key priority for healthcare providers, patients, and pharmaceutical companies. In this era of increasing automation, the use of innovative technologies and processes to ensure drug safety and pharmacovigilance has continually grown in importance. Automating drug safety and pharmacovigilance processes can lend an edge to organizations by reducing the burden of manual methods, providing better scalability, improved operational efficiency, and minimizing the risk of human errors. We are witnessing a few key trends across the industry in recent times.
Current Industry Trends towards smart case processing
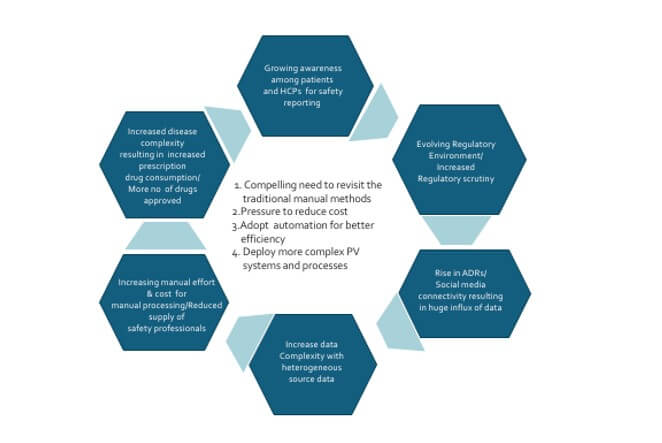
- As the cost of manual labour rises, there is an increased adoption of digital solutions to improve operational efficiency and reduce operational costs. More investments are seen in the development of pharmacovigilance tools and technologies. This can include the development of online databases, mobile applications, and software tools to facilitate the process of drug safety monitoring. In addition, digital solutions make it easier to analyse the data and extract insights that can help organizations optimize operations. Digital solutions provide several benefits for drug safety and pharmacovigilance
- Drug safety and pharmacovigilance activities are becoming increasingly automated when it comes to analysing large datasets, gathering adverse event reports, and more. Automation trends are rapidly changing the way drug safety and pharmacovigilance processes work, making them more efficient, effective. and less resource intensive
- Automation is reducing the time, effort and cost associated with data entry, document review and other manual processes. Automation can help streamline the process and reduce the risk of errors, by eliminating the need for manual data entry and providing a more detailed view of the data. It helps to improve compliance rate and data accuracy. It reduces resources needed for manual entry and review, also provide reliable results at faster pace. Automation can also simplify processes by making it easier to track and process large amounts of data. Additionally, automation can enable real-time alerts to be sent to quickly identify potential safety issues.
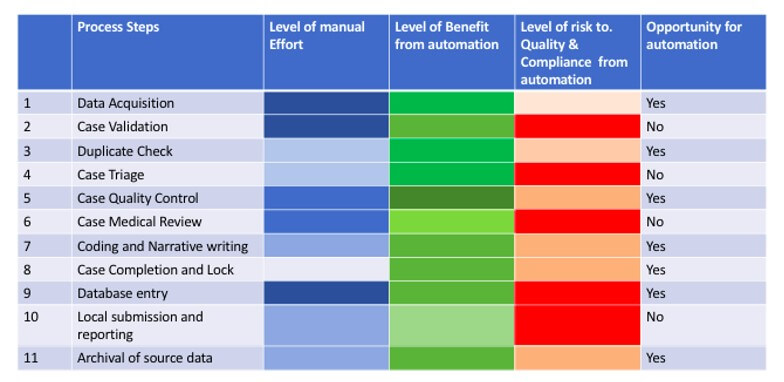
Though automation is highly beneficial, Intelligent automation is being explored across each process step within pharmacovigilance area to ensure compliance to the regulatory requirement and reduce risk due to automation. It is essential to break down and analyze each process step in terms of manual effort, automation potential, benefits, and risks to data quality and compliance. Once this has been done, this automation can be generically adopted by pharmacovigilance functions in various organisations despite organisational variations in specific process steps.
Introducing Navi-CADE:
In the age of digitalization, business processes are being automated using the latest technological advancements. The motivation behind these efforts is to make these processes agile and efficient. One of the business processes is involved in handling and processing large number of documents with different layouts, purpose and source. These can be structured documents like Loan Application Form, Insurance Claims, Tax Returns or unstructured like handwritten doctor prescription, legal contracts, scientific publication, and others.
Keeping in view of the wide spectrum of industries which need document processing solutions, we have developed Navi-CADE. Navi-CADE is a solution to search and process documents, using stack of extendible and reusable microservices, which can handle entire lifecycle of document processing, right from document ingestion to extracting domain entities and building ontologies. It is designed to handle documents both structured and unstructured across industries like Insurance, Taxation, Pharma and Lifesciences.
In addition to AI (Artificial Intelligence) services, we leverage custom built deep learning models like BERT for domain specific intelligence. For example, BioBERT is used to get in-depth domain understanding of medical text using wide spectrum of medical literature to provide contextual understanding using UMLS and other such resources. This will enable faster and efficient analysis of adverse event reports in case processing or further contributing towards case evaluation to detect a possible signal in pharmacovigilance. Another use case can be in loan processing where incoming loan application can be evaluated and preliminary evaluation can be done to check if loan can be approved or not based on the entities extracted from the documents and compared as per bank standards.
The key drivers of this solution are - reusable functionality, composing each individual functionality into a microservice, extending the functionality based on the business requirements, adopting latest tools and technologies to build an agile set of services and services which can be deployed quickly across different infrastructure setting.
An example of the real-life use case we have developed using this framework is - Case Processing in Pharmacovigilance. In this use case, we have used this framework's services to address processes starting from case ingestion through various channels like emails, database, and others, performing translation of the documents to English, extracting vital information from the documents to identifying key entities which supports case evaluation process and further extending their knowledge with the use of external medical journals and databases.
To understand how Navi-CADE can be used in current business processes, we need to know about the challenges being faced by the industry in document processing space. These challenges are -
- Quantum of documents being generated in today's digitalized world can overwhelm the legacy systems of document processing
- Diversity in the source and structure of these documents requires a solution to understand the document layout and then process it accordingly.
- Risks involved in some of the highly regulated industries like Insurance add another layer of complexity for the document processing solutions.
Keeping in mind these industry challenges, we have designed Navi CADE in such a manner that it gives flexibility to the business to deploy it as per their processes. Deployment of this framework involves -
- Defining the use case for which we would like to deploy this solution like processing loan applications or case processing in Pharmacovigilance
- Once we have identified the use case, we need to map the flow as per our business process
- We will define the possible sources of documents like in-house database, email server or cloud storage etc.
- Next, we define parser for our document based on the purpose, structure, and domain of the incoming documents. This is crucial to ensure reliable information extraction from the documents
- Then as per normal business process, along with our main form, we will have supporting documents like identity documents, address proofs, diagnostic results etc. We need a system to automatically identify and categorize these documents accordingly using custom document classification models.
- Once we know the category of each document, we can extract information and gather entities from the document for further deeper analysis.
- Finally, we would like to store all the results in a database and generate some summary report.
All these tasks can be performed by individual microservices, developed using underlying AI/ML services provided by AWS (Amazon Web Services) and this entire operation is orchestrated by an orchestrator which ensures all the tasks are performed sequentially.
The overall architecture of Navi-CADE can be categorized into three main service categories:
- AWS Services like Textract, to extract information from the documents, translate to perform translation, comprehend medical, to extract entities from the document information and map them further to external medical journals and databases using MEDRA coding
- Core Services perform generic document processing tasks using AWS Services mentioned earlier. These tasks are Ingestion of documents from diverse sources, performing translation, document classification, entity extraction and then using MEDRA cording to tag all the information to a standard medical term.
- Domain Services involves incorporating certain domain specific capabilities using state-of-the-art transformer models like BioBERT, LegalBERT and others. It also includes orchestration and pipeline capabilities.
Navi-CADE has been developed to address some of the key challenges faced by the industry like -
- Exponential Growth in the Documents generated at a particular point of time in an organization. With the rapid digitalization, the quantum of document processing requirements has made traditional processing capabilities ineffective and inextensible. The variety and veracity of documents makes processing even more complex and challenging.¯
- Documents are of several types and structure. Some are handwritten whereas some are attached with email files or could be stored in a datastore. Solution should be capable of handling documents of diverse design and coming from various sources.¯
- As different documents have different layouts it makes it extremely laborious to understand the structure of every document and then process it. Manual tasks are incapable of handling this complexity as they require documents to be in pre-defined structure only.
- Documents generated in highly regulated industry such as FSI and Pharma need to be handled with extra care due to the risk involved. ML (Machine Learning) / DL can play a key role in identifying such risks in the form of Terms, Contracts, Legal etc.
Navi-CADE can address all the above-mentioned challenges with the use of AI/ML services and automating and augmenting critical document processing tasks in an organization.
To discover more about how Navi-CADE and other innovative technologies can optimize your drug safety and pharmacovigilance processes, please reach out to us at marketing@navikenz.com