“We are generating 140 data elements per second across the two-wheeler segment where our battery is being used. How can we monetize this data?” This is what one of the clients mentioned in a discussion, which further led us to brainstorm the concept of ‘Data as a Service’ (DaaS). Until now, people have mostly heard about Software as a Service (SaaS). If we compare DaaS to SaaS, it works in a similar manner. Just as SaaS eliminates the need for software installation on devices and provides users with access to digital solutions over the network, DaaS also transfers most storage, integration, and processing operations to the cloud.
DaaS is essentially a data management strategy that utilizes the cloud to provide storage, integration, processing, and/or analytics services over a network connection. Data as a Service manages the stream of information and makes it accessible to all departments, anytime and anywhere. DaaS providers, like other “as a service” offerings, deliver data-centric insights through the cloud in a safe and cost-effective manner.
So, how does DaaS differ from Data as a Product (DaaP)?
During my research, I came across a post by Justin Gage (@itunpredictable) on Medium that explains the difference between DaaS and DaaP in the most simplistic fashion:
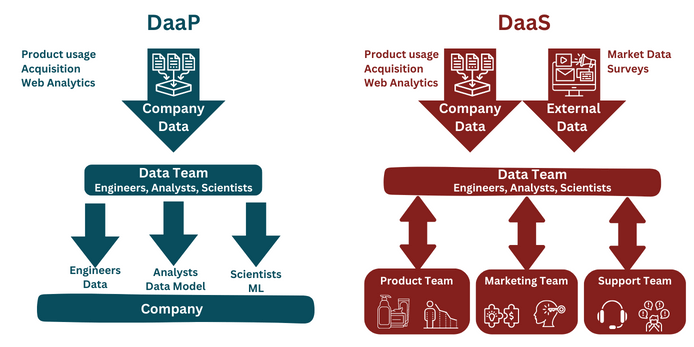
In the DaaP model, the company’s data is treated as a product, and the flow of data is unidirectional, from the data team to the company. In the Data as a Product model, the data team’s role is to deliver the data that the company requires for various purposes, such as making decisions, creating personalized products, or identifying fraud. It’s as simple as that.
In a DaaS model, the focus of the data team is on answering questions rather than providing tools for others to solve their own issues. The data team collaborates with stakeholder groups to address specific problems using data under the Data as a Service model.
When should a business consider DaaS?
The data market is continuously expanding, with new methods of obtaining data in various forms through growing connectivity tools such as mobile phones, IoT sensors, and more. These technologies provide new types of data and innovative methods for analysis. Some applications where DaaS can come in handy include:
-
Analyzing company growth: With DaaS, you have access to global external data, including market and competitor’s data. You can compare your company’s performance with market trends and see how competitors are faring in similar market conditions.
-
Monetizing big data: As the volume of big data increases, one of the biggest challenges for companies is turning this vast amount of data into actual revenue. Bringing data into your company is just the beginning; you need a plan to utilize the data acquired from your consumers to generate better brand experiences and achieve a return on the investment made in these robust systems.
-
Building a data marketplace: Users can buy and sell data on these platforms, bringing various types of data together, including demographic data from business intelligence platforms and consumer data from customer relationship management (CRM) systems. For data scientists, the ability to instantly buy and sell data is a valuable asset.
-
Improving customer experience: DaaS can assist businesses in creating personalized customer experiences by utilizing predictive analytics to better understand customers, identify trends, serve them better, and increase loyalty.
Final Remarks:
DaaS is well-positioned to deliver the features that today’s data-driven businesses desire, demand, or even require without their awareness. Despite being a relatively new solution, getting started with DaaS is easier than you may think. Please reach out to us for a deeper conversation about this topic.
For the past few decades, most companies have kept data in an organizational silo. Analytics teams served business units, and even as data became more crucial to decision-making and product roadmaps, the teams in charge of data pipelines were treated more like plumbers and less like partners.
In the current age, things have become different. The most forward-thinking teams are adopting a new paradigm: treating data like a product or DaaP. Fundamentally, Data as a Product is a concept, or methodology, about how data teams can create value in their organizations. Adopting an organizational approach of treating data like a product isn’t just a buzzworthy trend in the data industry. It’s an intentional shift in mindset that leads to meaningful outcomes: increasing data democratization and the ability to self-serve, improving data quality so decisions can be made accurately and confidently, and scaling the overall impact of data throughout the organization.
While approaching data as a product, organizations should think about the entire value chain from ingestion to consumer-facing data deliverables & what are the KPIs against which they want to measure the success of their data products. One must prioritize data quality and reliability throughout the data lifecycle. Data teams are working to find processes and systems that help them advocate for the importance of data on a wider organizational level. There are two broad mandates that data teams tend to get formed with:
- Provide data to the company
- Provide insights to the company
The job of the data team is to provide the data that the company needs, for whatever purpose, be it making decisions, building personalized products, or detecting fraud. This might just sound like data engineering, but it’s not. Many data teams are adopting KPIs related to data quality, such as calculating the cost of data downtime—times when data is partial, erroneous, missing, or otherwise inaccurate—or by measuring the amount of time data team members spend troubleshooting or fixing data quality issues, rather than focusing on innovations or building new data products.
Companies can assess their current state of data quality by mapping their progress against the data reliability maturity curve. Briefly, this model suggests there are four main stages of data reliability:
- Reactive: Teams spend most of their time responding to fire drills and triaging data issues—resulting in a lack of progress on important initiatives, an organizational struggle to use data effectively in their product, machine learning algorithms, or business decision-making.
- Proactive: Teams collaborate actively between engineering, data engineering, data analysts, and data scientists to develop manual checks and custom QA queries to validate their work.
- Automated: At this level, teams prioritize reliable, accurate data through scheduled validation queries that deliver broader coverage of pipelines. Teams use data health dashboards to view issues, troubleshoot, and provide status updates to others in the organization. Examples include tracking and storing metrics about dimensions and measures to observe trends and changes or monitoring and enforcing schema at the ingestion stage.
- Scalable: These teams draw on proven Dev Ops concepts to institute a staging environment, reusable components for validation, and/or hard and soft alerts for data errors. With substantial coverage of mission-critical data, the team can resolve most issues before they impact downstream users. Examples include anomaly detection across all key metrics and tooling that allows every job and table to be monitored and tracked for quality.
We, at Navikenz, have been helping organizations to move from stage 1 to 4 successfully. Also, over the past few years, companies have gotten wise to this, and have started using a different model (in consonance with DaaP) — Data as a Service. Will talk about DaaS in upcoming blogs.
Interested in transforming your organization’s approach to data? Contact us at marketing@navikenz.com to learn how we can help you move from reactive data management to scalable data reliability. Let Navikenz be your partner in creating a culture of data-driven decision-making and innovation in your organization.